Introduction
to .net Framework
.NET Framework generally consists of an environment for the
development and execution of programs, written in C# or some other language,
compatible with .NET (like VB.NET, Managed C++, J# or F#).
History
Overview of .NET
Framework release history

Definition
.NET
Framework (pronounced dot net) is a software framework
developed by Microsoft that runs primarily on Microsoft Windows. It includes a
large class library known as Framework Class Library (FCL) and provides language
interoperability (each language can use code written in other languages) across
several programming languages. Programs written for .NET Framework execute in a
software environment (as contrasted to hardware environment), known as Common
Language Runtime (CLR), and an application virtual machine that provides
services such as security, memory management, and exception handling. FCL and
CLR together constitute .NET Framework
Architecture
of .Net Framework

Instated
of learning architecture of .Net Framework we will learn how execute a program
inside .Net Framework, then automatically you will know the architecture of
.Net Framework.
Process
of executing .Net Program in .Net Framework
1.
Programming Language
2.
Compiler
2.1
MSIL
2.2Metadata
2.3 portable executable (PE)
2.4Managed Code
3.
Common Language Runtime(CLR)
4.
Compiling
MSIL to Native Code
4.1
A .NET
Framework just-in-time (JIT) compiler
4.2 The .NET Framework Native Image Generator (Ngen.exe)
4.3 Code Verification
5 Managed Execution Process
6.
Executing an Instruction
7.
Other Component
7.1
.NET Framework Base Class Library
7.2 Common
Type System
Relationship to the Common
Type System and the Common Language Specification
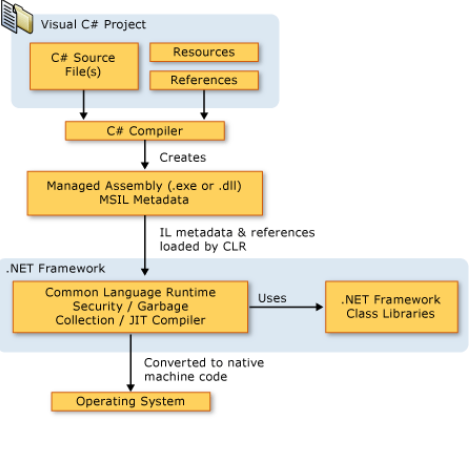
1]
Programming Language:
For the .Net programming we need Visual Studio IDE. We will
not learn Visual Studio but History of Visual Studio.

2] Compiler:
Each
language has its own compiler which is use for converting high level language (Human
readable) to Microsoft Intermediate Language (MSIL or IL or Managed Code).
I] MSIL:
When
compiling to managed code, the compiler translates your source code into
Microsoft intermediate language (MSIL), which is a CPU-independent set of
instructions that can be efficiently converted to native code. MSIL includes
instructions for loading, storing, initializing, and calling methods on
objects, as well as instructions for arithmetic and logical operations, control
flow, direct memory access, exception handling, and other operations. Before
code can be run, MSIL must be converted to CPU-specific code, usually by a just-in-time
(JIT) compiler. Because the common language runtime supplies one or more JIT
compilers for each computer architecture it supports, the same set of MSIL can
be JIT-compiled and run on any supported architecture.
When
a compiler produces MSIL, it also produces metadata. Metadata describes the
types in your code, including the definition of each type, the signatures of
each type's members, the members that you’re code references, and other data
that the runtime uses at execution time. The MSIL and metadata are contained in
a portable executable (PE) file that is based on and extends the published
Microsoft PE and common object file format (COFF) used historically for
executable content. This file format, which accommodates MSIL or native code as
well as metadata, enables the operating system to recognize common language
runtime images. The presence of metadata in the file along with the MSIL
enables your code to describe itself, which means that there is no need for
type libraries or Interface Definition Language (IDL). The runtime locates and
extracts the metadata from the file as needed during execution.
II)
Meta
Data:
Metadata is binary information describing your program
that is stored either in a common language runtime portable executable (PE)
file or in memory. When you compile your code into a PE file, metadata is
inserted into one portion of the file, while your code is converted to
Microsoft intermediate language (MSIL) and inserted into another portion of the
file. Every type and member defined and referenced in a module or assembly is
described within metadata. When code is executed, the runtime loads metadata into
memory and references it to discover information about your code's classes,
members, inheritance, and so on.
Metadata describes every type and member defined in your
code in a language-neutral manner. Metadata stores the following information:
- Description of the assembly.
o
Identity (name,
version, culture, public key).
o
The types that are
exported.
o
Other assemblies
that this assembly depends on.
o
Security
permissions needed to run.
- Description of types.
o
Name, visibility,
base class, and interfaces implemented.
o
Members (methods,
fields, properties, events, nested types).
- Attributes.
o
Additional
descriptive elements that modify types and members.
III)
portable executable(PE):
The file format
defining the structure that all executable files (EXE) and Dynamic Link
Libraries (DLL) must use to allow them to be loaded and executed by Windows. PE
is derived from the Microsoft Common Object File Format (COFF). The EXE and DLL
files created using the .NET Framework obey the PE/COFF formats and also add
additional header and data sections to the files that are only used by the CLR.
Format of .Net PE file

IV)
Managed vs Unmanaged Code:
Manage Code:
Managed code is code that
is written to target the services of the managed runtime execution environment
(like Common Language Runtime in .NET Framework). The managed
code is always executed by a managed runtime execution environment rather than
the operating system directly. Managed refers to a method of exchanging
information between the program and the runtime environment. Because the
execution of code is governed by the runtime environment, the environment can
guarantee what the code is going to do and provide the necessary security
checks before executing any piece of code.
In .NET Framework Managed
Code runs within the .Net Framework’s CLR and benefits from the services
provided by the CLR. When we compile the managed code, the code gets compiled
to an intermediate language (MSIL) and an executable is created.
Managed code also called as
MSIL or IL.
Unmanaged Code:
Code that is directly
executed by the Operating System is known as unmanaged code. Typically
applications written in VB 6.0, C++, C, etc are all examples of unmanaged code.
Unmanaged code typically targets the processor architecture and is always
dependent on the computer architecture. Unmanaged code is always compiled to
target a specific architecture and will only run on the intended platform. This
means that if you want to run the same code on different architecture then you
will have to recompile the code using that particular architecture. Unmanaged
code is always compiled to the native code which is architecture specific. When
we compile unmanaged code it gets compiled into a binary X86 image. And this
image always depends on the platform on which the code was compiled and cannot
be executed on the other platforms that are different that the one on which the
code was compiled. Unmanaged code does not get any services from the managed
execution environment. In unmanaged code the memory allocation, type safety,
security, etc. needs to be taken care of by the developer.
3] Common Language Runtime (CLR):
The Common Language Runtime
(CLR) is an Execution Environment. It works as a layer between Operating
Systems and the applications written in .Net languages that conforms to the
Common Language Specification (CLS). The main function of Common Language
Runtime (CLR) is to convert the Managed Code into native code and then execute
the Program.

The
Managed Code compiled only when it needed, that is it converts the appropriate
instructions when each function is called. The Common Language Runtime (CLR)’s Just
In Time (JIT) compilation converts Intermediate Language (MSIL) to native code
on demand at application run time.
During the execution of the
program, the Common Language Runtime
(CLR) manages memory, Thread execution, Garbage Collection (GC), Exception Handling, Common Type
System (CTS), code safety verifications, and other system services. The CLR (Common Language Runtime) defines the Common Type
System (CTS), which is a standard type system used by all .Net languages. That means all .NET
programming languages uses the same representation for common Data Types, so Common Language Runtime
(CLR) is a language-independent runtime environment. The Common Language Runtime (CLR) environment is
also referred to as a managed environment, because during the execution of a
program it also controls the interaction with the Operating System.
4] Compiling
MSIL to Native Code:
- A .NET Framework just-in-time (JIT) compiler.
- The .NET Framework Native Image Generator (Ngen.exe)
- Code Verification
I)
A .NET
Framework just-in-time (JIT) compiler:
·
JIT compilation
converts MSIL to native code on demand at application run time, when the
contents of an assembly are loaded and executed. Because the common language
runtime supplies a JIT compiler for each supported CPU architecture, developers
can build a set of MSIL assemblies that can be JIT-compiled and run on
different computers with different machine architectures. However, your managed
code will run only on a specific operating system if it calls platform-specific
native APIs, or a platform-specific class library.

·
JIT compilation
takes into account the fact that some code might never get called during
execution. Rather than using time and memory to convert all the MSIL in a
portable executable (PE) file to native code, it converts the MSIL as needed
during execution and stores the resulting native code in memory so that it is
accessible for subsequent calls in the context of that process. The loader
creates and attaches a stub to each method in a type when the type is loaded
and initialized. When a method is called for the first time, the stub passes
control to the JIT compiler, which converts the MSIL for that method into
native code and modifies the stub to point directly to the generated native
code. Subsequent calls to the JIT-compiled method therefore proceed directly to
the native code.



Different Types of JIT :
1] Normal JIT :
This complies only that part of code which called at runtime. That code are compiled only first time when they are called, and then they are stored in memory cache. This memory cache is commonly called as JITTED. When the same methods are called again, the complied code from cache is used for execution.
2] Econo JIT :
This complies only methods that are called at run-time and removes them from memory after execution.
3] Pre JIT :
This complies entire MSIL code into native code in a single compilation cycle. This is done at the time of deployment of the application.
II) The .NET Framework Native Image
Generator (Ngen.exe):
- It performs the conversion from MSIL to native code before rather than while running the application.
- · It compiles an entire assembly at a time, rather than a method at a time.
- It persists the generated code in the Native Image Cache as a file on disk.
III)
Code
Verification :
The runtime relies on the fact that the following statements are true for code that is verifiably type safe:
- A reference to a type is strictly compatible with the type being referenced.
- Only appropriately defined operations are invoked on an object.
- Identities are what they claim to be.
5] Managed Execution Process
Managed code is self-explanatory code which gives information to CLR for multiple runtime services in .NET Framework.
This information is stored in MSIL code in the form of metadata inside the PE file. Mata data information will describe the types that the code contains.
Managed data is allocated and released from memory automatically by garbage collection. Managed data can be accessible form managed code but managed code can be accessible from managed and unmanaged data.
Memory Management
Automatic memory management means no need to write code to allocate memory when objects are created or to release memory when objects are not required the application.
The process of automatic memory management involves the following tasks:
1] Allocating memory
When a process is initialized, the runtime reserves a contiguous address space without allocating any storage space for it. This reserved address space is called a managed heap. The managed heap keeps a pointer at the location where the next object will be located. When an application uses the new operator to create an object, the new operator checks whether the memory required by the object is available on the heap.
When the next object is created, the garbage collector allocates memory to the object on the managed heap, Allocating memory to the objects in a managed heap takes less time than allocating unmanaged memory. In unmanaged memory, the pointers to memory are maintained in linked-list data structures. Therefore, allocating memory requires navigating through the linked list, finding a large memory block to accommodate the
You can access objects in managed memory faster than objects in unmanaged memory because in managed memory allocation, objects are created contiguously in the managed address space.
2] Releasing Memory
The garbage collector periodically releases memory from the objects that are no longer required by the application.
Every application has a set of roots. Roots point to the storage location on the managed heap. Each root either refers to an object on the managed heap or is set to null. An application's roots consist of global and static object pointers, local variables, and reference object parameters on a thread stack. The JIT compiler and the run-time maintain the list of the application roots. The garbage collector uses this list to create a graph of objects on the managed heap that are reachable from the root list.
When the garbage collector starts running, it considers all the objects on the managed heap as garbage. The garbage collector navigates through the application root list, it identifies the objects that have corresponding references in the application root list and marks them as reachable. The garbage collector also considers such objects as reachable objects. The garbage collector considers all unreachable objects on the managed heap as garbage.
The garbage collector performs a collection process to free the memory occupied by the garbage objects. The garbage collector performs the memory copy function to compress the objects in the managed heap. The garbage collector updates the pointers in the application root list so that the application roots correctly point to the objects to which they were pointing earlier. The garbage collector uses a highly optimized mechanism to perform garbage collection. It divides the objects on the managed heap into three generations: 0, 1, and 2. Generation 0 contains recently created objects. The garbage collector first collects the unreachable objects in generation 0. Next, the garbage collector compacts memory and promotes the reachable objects to generation 1. The objects that survive the collection process are promoted to higher generations.
The garbage collector searches for unreachable objects in generations 1 and 2 only when the memory released by the collection process of generation 0 objects is insufficient to create the new object. The garbage collector manages memory for all managed objects created by the application. The garbage collection can explicitly release these system resources by providing the cleanup code in the Dispose method of the object. We need to explicitly call the Dispose method after you finish working with the object.
3]Implementing Finalizers
The finalization process allows an object to perform cleanup tasks automatically before garbage collection starts.
The
Finalize method ensures that even if the client does not call the Dispose method explicitly, the resources used by the object are released from memory when the object is garbage collected. After the garbage collector identifies the object as garbage during garbage collection, it calls the Finalize method on the object before releasing memory. Finalizers are the methods that contain the cleanup code that is executed before the object is garbage collected. The process of executing cleanup code is called finalization. The Dispose and Finalizemethods are called finalizers.
The
Dispose method of an object should release all its resources in addition to the resources owned by its parent object by calling the Dispose method of the parent object.
We can execute the
Dispose method in two ways.- The user of the class can call the
Disposemethod on the object that is being disposed, or - The
Finalizemethod can call theDisposemethod during the finalization process.
6]
Executing an Instruction:
Finally OS
take instructions form CLR and give to processor and processor execute it and
give the result.
7]
Other Component:
1.
.NET Framework Base Class Library
The .NET Framework class
library is a library of classes, interfaces, and value types that provide
access to system functionality. It is the foundation on which .NET Framework
applications, components, and controls are built. The namespaces and namespace
categories in the class library are listed in the following table and
documented in detail in this reference. The namespaces and categories are
listed by usage, with the most frequently used namespaces appearing first.

2.
Common Type System
The common type system defines how types are declared, used, and managed in the common language runtime, and is also an important part of the runtime's support for cross-language integration.
The specification for the CTS is contained in Ecma standard 335, "Common Language Infrastructure (CLI) Partitions I to VI." The CLI and the CTS were created by Microsoft, and the Microsoft .NET framework is an implementation of the standard.

The common type system supports two general categories of
types, each of which is further divided into subcategories:
v Value types :
Value types directly contain their data, and instances of
value types are either allocated on the stack or allocated inline in a
structure. Value types can be built-in (implemented by the runtime),
user-defined, or enumerations. For a list of built-in value types, see the .NET
Framework Class Library.
v Reference types :
Reference types store a reference to the value's memory
address, and are allocated on the heap. Reference types can be self-describing
types, pointer types, or interface types. The type of a reference type can be
determined from values of self-describing types. Self-describing types are
further split into arrays and class types. The class types are user-defined
classes, boxed value types, and delegates.
Variables that are value types each have their own copy
of the data, and therefore operations on one variable do not affect other
variables. Variables that are reference types can refer to the same object;
therefore, operations on one variable can affect the same object referred to by
another variable.
All types derive from the System. Object base type.
3.
Relationship
to the Common Type System and the Common Language Specification
The Common Type System is the model that defines the
rules the common language runtime follows when declaring, using, and managing
types. The common type system establishes a framework that enables
cross-language integration, type safety, and high-performance code execution.
It is the raw material from which you can build class libraries.
The Common Language Specification (CLS) defines a set of
programmatically verifiable rules that governs the interoperation of types
authored in different programming languages. Targeting the CLS is an excellent
way to ensure cross-language interoperation. Managed class library designers
can use the CLS to guarantee that their APIs are callable from a wide range of
programming languages. Note that although the CLS encourages good library
design, it does not enforce it. You should follow two guiding principles with
respect to the CLS when determining which features to include in your class
library:
1.
Determine whether
the feature facilitates the type of API development appropriate to the managed
space.
The CLS should be rich
enough to provide the ability to write any managed library. However, if you
provide multiple ways to perform the same task, you can confuse users of your
class library about correct design and usage. For example, providing both safe
and unsafe constructs forces users to decide which to use. Therefore, the CLS
encourages the correct usage by offering only type-safe constructs.
2.
Determine whether
it is difficult for a compiler to expose the feature.
All programming
languages will require some modification in order to target the runtime and the
common type system. However, in order for developers to make a language
CLS-compliant, they should not have to create a large amount of additional
work. The goal of the CLS is to be as small as possible while offering a rich
set of data types and features.
I hope it will helpful for .Net beginners.
The all above information collected from internet if any
query please inform me.
Resources:
1.
MSDN
2.
Wikipedia
3. http://www.dotnet-tricks.com
3. http://www.dotnet-tricks.com
Created and Edited By
Ashutosh Ashok Jagtap,
(ashujagtap333@gmail.com)